
 English (United Kingdom)
English (United Kingdom)  Italiano (Italia)
Italiano (Italia) AI Technologies
With this article I would like to illustrate one of the most recent trends in Artificial Intelligence, called "Talking Heads".
The origin of this particular AI technology dates back to a publication by researchers from the Samsung AI Center in Moscow a little over a year ago, which can be downloaded from this link on Cornell University's arXiv.org site. In practice, it allows you to build realistic videos of subjects starting even from a single image (or photo) of the subject itself, this obviously means that the subject may not even be real, as in the following example.
 |
 |
 |
 |
 |
Mona Lisa – Leonardo da Vinci
The system allows you to create realistic 3D models that portray the head and face of any individual, moving these models produce videos in different cases indistinguishable from the original ones.
The system uses AI to reconstruct the 3D model and facial movements. Although it is possible to build everything starting from a single photo, as in the case of the example, the more photos you use for the learning phase, the better the final result will be.
The technology uses 3 distinct types of neural networks, each dedicated to process specific information.
A first network analyzes the frames produced by a video that shoots a person (we can define him as the hidden actor), extracts the characteristics of the face by combining them together in order to create a vector model of the skeleton of the face accompanied by the characteristic elements (eyes, mouth, nose, etc.), defined landmarks, in order to build different facial expressions.
The second neural network is responsible for producing a "synthesized" model by applying the textures (skin, eyes, beard, clothes, etc.) obtained from the starting images to the 3D model produced by the first network.
Finally, the third network compares each frame generated by the 3D model with the original ones, eliminating unrealistic images in order to preserve both the identity of the final subject of the video (Mona Lisa in the example) and the gestures of the hidden actor; in practice it applies the movements and facial expressions of the hidden actor to the subject of the film.

The previous image shows respectively, the hidden actor, the 3D model of the facial expression and the same applied to the subject of the movie.
The basic scheme of what is described is illustrated in the following image (taken from the aforementioned publication).
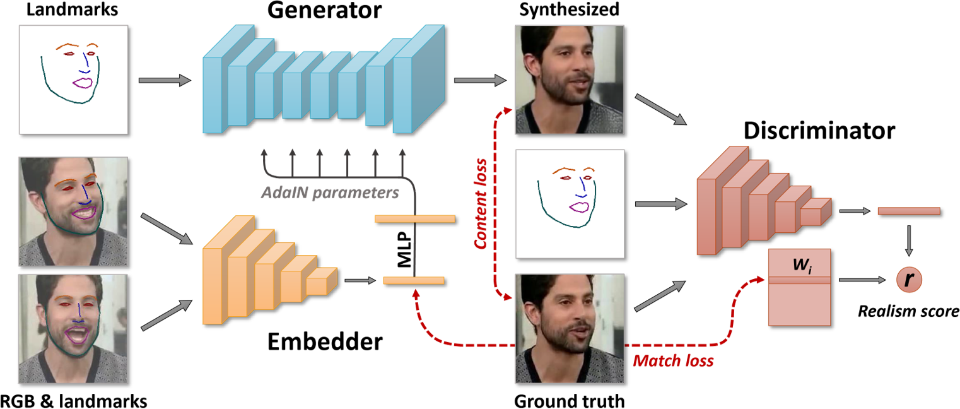
Note that the model used also produces a "Realism Score" (r), on the basis of which to eliminate unrealistic images.
Other examples of Talking Heads built from a single image are the following.
 |
 |
 |
 |
 |
The Maid of Honor of the Infanta Isabella - Peter Paul Rubens
 |
 |
 |
 |
 |
Girl with a Turban (incorrectly called Girl with a Pearl Earring) - Jan Vermeer
 |
 |
 |
 |
 |
Portrait of an Unknown Woman - Ivan Nikolaevič Kramskoj
Finally, some really impressive footage.
The first shows Salvador Dalì and was created by the technicians of the Dalì Museum in St. Petersburg in Florida; you can view it at this link.
The second shows Barack Obama who is made to say: "We're entering an era in which our enemies can make anyone say anything at any point in time" and "President Trump is a total and complete dipshit"; you can view it at this link.
The third, finally, is of Italian production and is a joke of the television program Le Iene to Matteo Renzi; you can view it from this link.
