
 Italiano (Italia)
Italiano (Italia)  English (United Kingdom)
English (United Kingdom) Tecnologie di IA
Con questo articolo desidero illustrare una delle più recenti tendenze dell’Intelligenza Artificiale, definita “Teste Parlanti”.
L’origine di questa particolare tecnologia dell’IA risale a una pubblicazione di ricercatori del Samsung AI Center di Mosca di poco più di un anno fa, che può essere scaricata da questo link del sito arXiv.org della Cornell University. Essa in pratica permette di costruire video realistici di soggetti a partire anche da una sola immagine (o foto) del soggetto stesso, questo ovviamente significa che il soggetto può anche non essere reale, come nell’esempio seguente.
 |
 |
 |
 |
 |
Mona Lisa – Leonardo da Vinci
Il sistema consente di creare realistici modelli 3D che ritraggono testa e volto di qualunque individuo, tali modelli vengono quindi fatti muovere producendo dei filmati in diversi casi indistinguibili dai video originali.
Il sistema utilizza l’IA per la ricostruzione dei modello 3D e dei movimenti facciali. Sebbene sia possibile costruire il tutto a partire da una sola foto, come nel caso dell’esempio, più foto si utilizzano per la fase di apprendimento migliore sarà il risultato finale.
La tecnologia utilizza 3 distinti tipi di reti neurali, ciascuna dedicata all’elaborazione di specifiche informazioni.
Una prima rete analizza i fotogrammi prodotti da un video che riprende una persona qualsiasi (lo possiamo definire l’attore nascosto), ne estrae le caratteristiche del volto combinandole tra loro in modo da creare un modello vettoriale dello scheletro del volto corredato dagli elementi caratteristici (occhi, bocca, naso, etc.), definiti landmarks, in modo da costruire differenti espressioni facciali.
La seconda rete neurale si occupa di produrre un modello “sintetizzato” applicando al modello 3D prodotto dalla prima rete le texture (pelle, occhi, barba, vestiti, etc.) ricavate dalle immagini di partenza.
La terza rete infine confronta ogni fotogramma generato dal modello 3D con quelli originali eliminando le immagini poco realistiche in modo da preservare sia l’identità del soggetto finale del video (Monna Lisa nell’esempio), sia la gestualità dell’attore nascosto; in pratica applica i movimenti e le espressioni facciali dell’attore nascosto al soggetto del filmato.

L’immagine precedente mostra rispettivamente, l’attore nascosto, il modello 3D dell’espressione facciale e lo stesso applicato al soggetto del filmato.
Lo schema di principio di quanto descritto è illustrato nell’immagine seguente (tratta dalla suddetta pubblicazione).
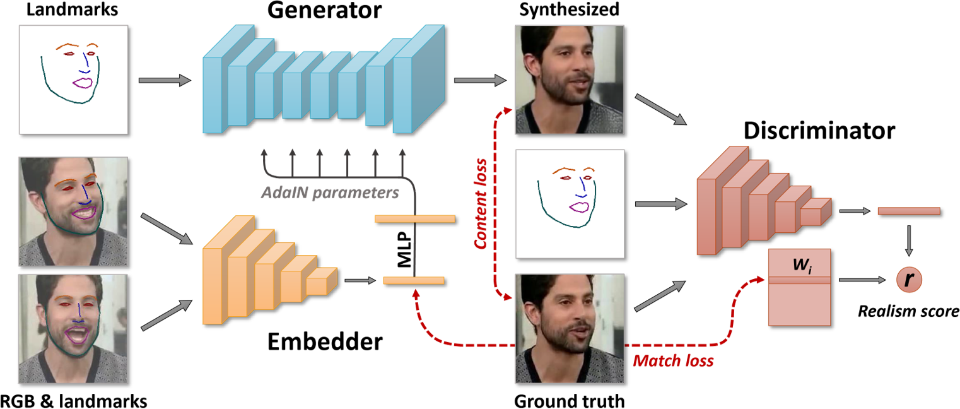
Da notare che il modello utilizzato produce anche un “Punteggio di Realismo” (r), in base al quale eliminare le immagini poco realistiche.
Altri esempi di Teste Parlanti costruite a partire da una singola immagine sono le seguenti.
 |
 |
 |
 |
 |
La Damigella d'Onore dell'Infanta Isabella - Peter Paul Rubens
 |
 |
 |
 |
 |
Ragazza col Turbante (impropriamente detta Ragazza con l’Orecchino di Perla) - Jan Vermeer
 |
 |
 |
 |
 |
Ritratto di Donna Sconosciuta - Ivan Nikolaevič Kramskoj
Per finire alcuni filmati davvero impressionanti.
Il primo mostra Salvator Dalì ed è stato realizzato dai tecnici del Dalì Museum di St. Petersburg in Florida; è possibile visualizzarlo a questo link.
Il secondo mostra Barack Obama al quale, tra l’altro, fanno dire: "Stiamo entrando in un'era in cui i nostri nemici possono far dire qualsiasi cosa a chiunque in qualsiasi momento" e "Il presidente Trump è un idiota totale e completo"; è possibile visualizzarlo da questo link.
Il terzo, infine, è di produzione Italiana ed è uno scherzo del programma televisivo Le Iene a Matteo Renzi; è possibile visualizzarlo da questo link.
